C++ Primer
A standout project in Andy Pavlo’s 15-445/645 course on database systems is Project 0: C++ Primer which asseses your knowledge of basic C++ features like:
- references
- std::move
- templated functions and classes
- smart pointers
- locks
- STL containers (std::set, std::vector, std::unordered_map)
This mandatory project is supposedly a self-evaluation safety mechanism for students on 15-445 to ensure they have enough C++ preparation to finish the course. Therefore, if you’re brushing up on your C++ skills then completing this project is an excellent goal.
Make sure to get into the habit of referring to the core language standards and style while writing your code:
This project builds a concurrent key-value store backed by a copy-on-write trie. You can find the starting code in the BusTub repository created for this course (we will only be dealing with Project 0).
$ git clone https://github.com/cmu-db/bustub.git
$ cd bustub
# macOS
$ build_support/packages.sh
$ mkdir build && cd build
$ cmake -DCMAKE_BUILD_TYPE=Debug ..
$ make -j`nproc`
We can test our using the four in-built GTest unit test cases.
$ cd build
$ make trie_test trie_store_test -j$(nproc)
$ make trie_noncopy_test trie_store_noncopy_test -j$(nproc)
$ ./test/trie_test
$ ./test/trie_noncopy_test
...
If you are interested in using gdb for debugging, then you might like this presentation by Greg Law.
Copy-on-write KV store
Copy-on-write (COW) is a common strategy used to resolve concurrency and reliability issues. Essentialy, any update operation to an original, shared resource requires a new, private copy to be made and parts of the original copy which are unchanged are re-used in the private copy. This approach is seen in network file servers like:
- NetApp’s Write Anywhere File Layout (WAFL)
- ZFS (Sun/Oracle)
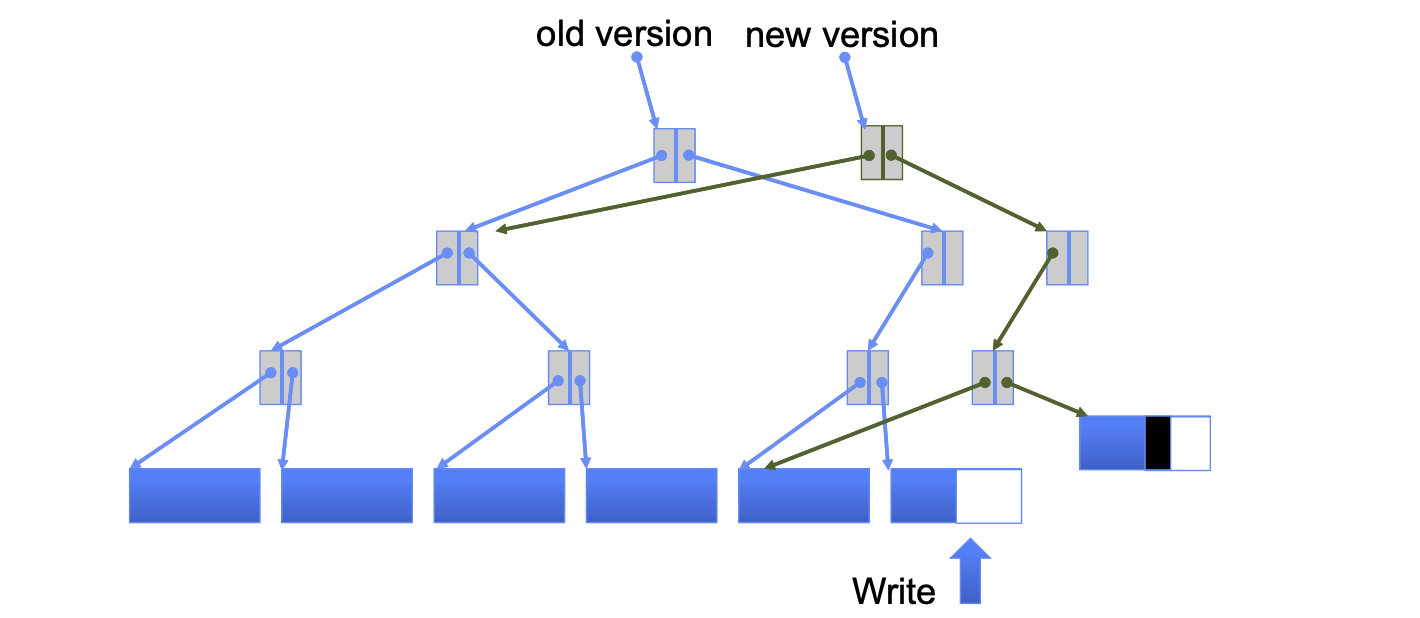
The transactional/atomic nature of COW is apparent because if the write operation is interrupted (i.e., if a crash occurs in the middle), then the state of the old version is unchanged. Transactions only update the old version when they are committed, which in this case means persisting the new version. Old version pointers can be stored as snapshots to provide instant and cheap backups.
It shouldn’t come as a surprise to see COW also being used as a synchronisation mechanism for shared daat structures. Although, it comes in the form of read-copy-update (RCU), a very common non-blocking algorithm. COW-backed data structures share the following properties with RCU.
- RCU is completely wait-free for any number of readers.
- Single-writer implementations RCU are also lock-free for the writer.
- Multi-writer implementations of RCU serialize writers with a lock.
- Fast reading operations are enabled at the cost of more space.
Contrast these properties with regular read-write locks that only allows concurrent execution of multiple readers.
We will implement COW using an ordered search tree data structure called trie in which keys (commonly variable-length strings) are mapped to values (of any arbitrary type) in nodes.

In the above example, inserting (“ad”, 2) requires cloning all nodes living above (ancestors of) the final node. Exisitng nodes are re-used as much as possible. We are given the following definition of the Trie class in C++.
namespace bustub {
// A TrieNode is a node in a Trie.
class TrieNode {
public:
TrieNode() = default;
explicit TrieNode(std::map<char, std::shared_ptr<const TrieNode>> children) : children_(std::move(children)) {}
virtual ~TrieNode() = default;
virtual auto Clone() const -> std::unique_ptr<TrieNode> { return std::make_unique<TrieNode>(children_); }
// A map of children, where the key is the next character in the key, and the value is the next TrieNode.
std::map<char, std::shared_ptr<const TrieNode>> children_;
bool is_value_node_{false};
};
// A TrieNodeWithValue is a TrieNode that also has a value of type T associated with it.
template <class T>
class TrieNodeWithValue : public TrieNode {
public:
// Create a trie node with no children and a value.
explicit TrieNodeWithValue(std::shared_ptr<T> value) : value_(std::move(value)) { this->is_value_node_ = true; }
TrieNodeWithValue(std::map<char, std::shared_ptr<const TrieNode>> children, std::shared_ptr<T> value)
: TrieNode(std::move(children)), value_(std::move(value)) {
this->is_value_node_ = true;
}
// Override the Clone method to also clone the value.
auto Clone() const -> std::unique_ptr<TrieNode> override {
return std::make_unique<TrieNodeWithValue<T>>(children_, value_);
}
// The value associated with this trie node.
std::shared_ptr<T> value_;
};
// A Trie is a data structure that maps strings to values of type T. All operations on a Trie should not
// modify the trie itself.
class Trie {
private:
std::shared_ptr<const TrieNode> root_{nullptr};
explicit Trie(std::shared_ptr<const TrieNode> root) : root_(std::move(root)) {}
public:
// Create an empty trie.
Trie() = default;
template <class T>
auto Get(std::string_view key) const -> const T *;
template <class T>
auto Put(std::string_view key, T value) const -> Trie;
auto Remove(std::string_view key) const -> Trie;
auto GetRoot() const -> std::shared_ptr<const TrieNode> { return root_; }
};
}
Copy-on-write trie
We get to implement the API by supporting the three Get(key), Put(key, value) and Delete(key) operations. A recap of all the rules so far:
- None of these operations should be performed directly on the trie itself.
- Parent nodes can have values too.
- Empty terminal nodes must be purged.
- Put and Delete return new tries.
I won’t be writing code here as compliant with Andy Pavlo’s policy on creating a fair learning environment. I will only be giving the intuition behind my solution and explore some relevant C++ caveats/asides.
Get(key)
Get the value corresponding to the key.
This is a straightforward lookup on thestd::map associated with each TrieNode. If the key is "abc",then root[a][b][c] should give us the TrieNode we’re looking for. If any of the access operations fail, then we fail.
To get the value, we need to downcast the TrieNode to TrieNodeWithValue<T> but note that this node may have been constructed as a plain TrieNode (it doesn’t contain a value). Casting this may cause unexpected run-time behaviour.
auto value_node = static_cast<const TrieNodeWithValue<T> *>(f_node.get()); // compiles fine
value_node.value(); // if f_node was not constructed as TrieNodeWithValue then we have a problem
A good fix here is to use dynamic_cast<> instead which returns a nullptr if the underlying object type doesn’t match with target cast type.
auto value_node = dynamic_cast<const TrieNodeWithValue<T> *>(f_node.get()); // compiles fine
if (value_node) {
...
}
You may have noticed the emphasis in the previous line. How does dynamic_cast<> know what the underlying object type is and if the downcast if safe?
That’s because C++ adds run-time type information (RTTI) to the program image which exposes information about an object’s data type. This would obviously increase the size of the image in memory and affect performance.
Note that RTTI only works with polymorphic classes. These are marked using the virtual keyword for class methods in C++. Why does it only work with polymorphic classes? Because the generic C++ ABI dictates that it does! The virtual method table (vtable) used to support dynamic dispatch in C++ contains the type information necessary to compare pointers.

Consider the above example which gives us a rough layout of a vtable for a sample class A which includes function pointers to virtual functions inside the class and a 64-bit pointer to a structure giving us RTTI.
The Itanium C++ ABI, which was originally written for the Itanium architecture, serves as a generic specification which can be used by C++ implementations on a variety of platforms. The ABI states,
A virtual table (vtable) is a table of information used to dispatch virtual functions, to access virtual base class subobjects, and to access information for runtime type identification (RTTI)… The typeinfo pointer points to the typeinfo object used for RTTI. It is always present. All entries in each of the virtual tables for a given class must point to the same typeinfo object. The typeinfo pointer is a valid pointer for polymorphic classes, i.e. those with virtual functions, and is zero for non-polymorphic classes.
The std::type_info structure which looks something like this:
namespace std {
class type_info {
public:
virtual ~type_info();
bool operator==(const type_info &) const;
bool operator!=(const type_info &) const;
bool before(const type_info &) const;
const char* name() const;
private:
type_info (const type_info& rhs);
type_info& operator= (const type_info& rhs);
};
}
So, all dynamic_cast has to do is check the equality of types is to check the equality of pointers and then performs the cast. Awesome!
Put(key, value)
Set the corresponding value to the key. Overwrite existing value if the key already exists. This method returns a new trie.
This is more challenging to implement than Get(key) but is straightforward to think about. Recall we cannot change the original trie at all. So, every node which comes before root[key[0]][key[1]].. in the original trie needs to be cloned. And if such nodes do not exist, then they are constructed. We use simple pointers to connect these nodes.
// `T` type of value might be a non-copyable type
std::shared_ptr<T> value_ptr = std::make_shared<T>(std::move(value));
// Two pointers to connect together nodes in the new trie
std::shared_ptr<TrieNode> new_node;
std::shared_ptr<TrieNode> new_node_parent;
// A pointer to navigate the old trie
std::shared_ptr<TrieNode> old_node;
//...
//...
// While navigating the old trie, if old_node exists then clone it. Else, create a new one
new_node = old_node ? old_node->Clone() : std::make_shared<TrieNode>();
// Connect together new_node and its parent
//...
The most interesting thing we can talk about here is std::move‘ing our input T value to std::shared_ptr. How does std::move really work?
More keen observers will also have noticed that I assigned old_node->Clone() which is std::unique_ptr to new_node which is a std::shared_ptr. Why is that possible?
Well, the concept behind this is actually quite simple to understand (we won’t discuss universal referencing) and it’s called move semantics. But first, let’s recall how and why we use call by reference.
- We may need to call functions that mutate parameters which return information back to the caller (also called out parameter). These are non-const references.
- We have const references which cannot be mutated but also need not be copied to be used inside our function.
Introduced in C++11, move semantics allowed rvalues to become modifiable (become non-const) after being initialised. These are identified using T&& and are called rvalue references. What are rvalues? This amazing slide by Nicolai Josuttis makes it clear.
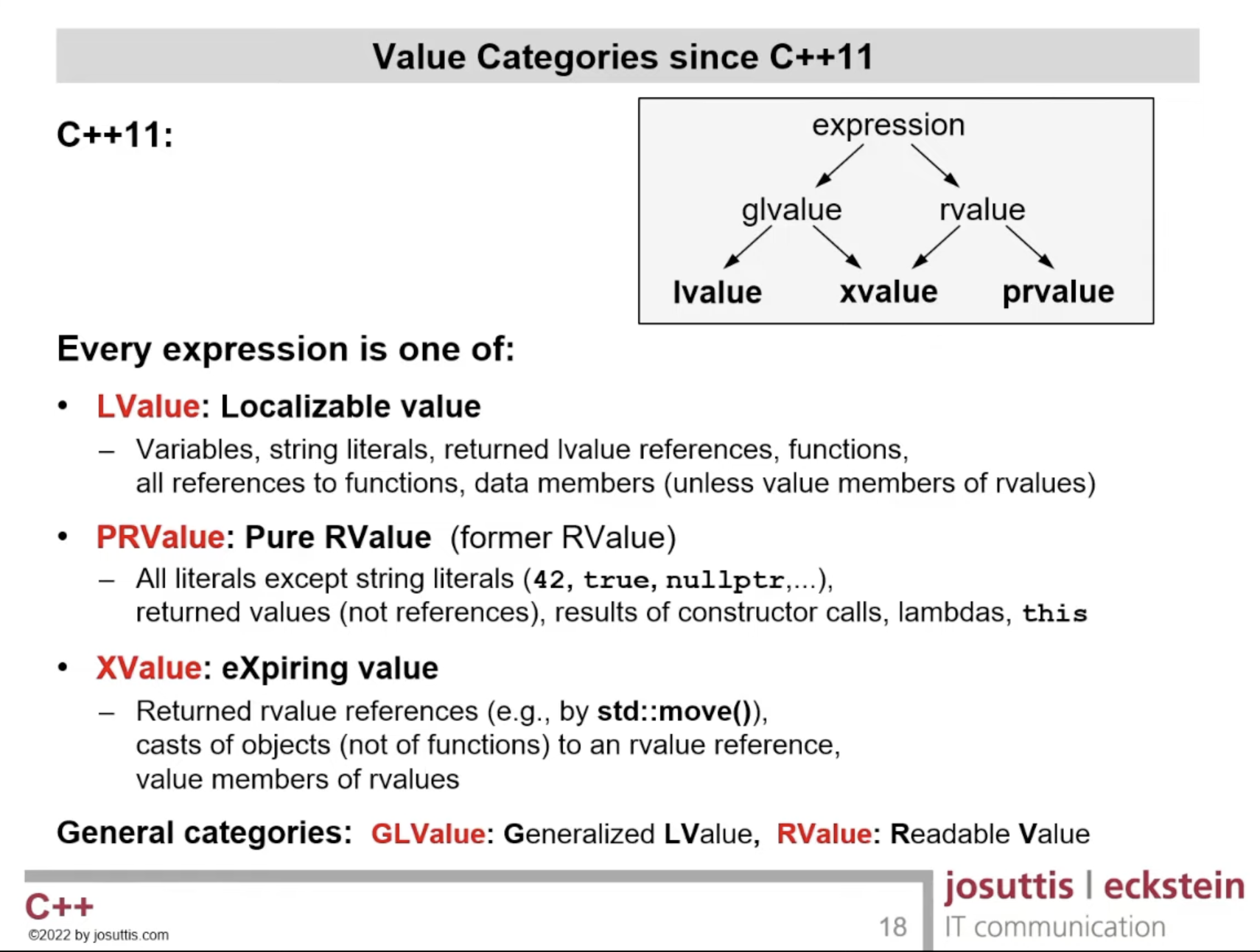
- lvalues are everything that has a name and string literals
- prvalues are temporaries without name and non-string literals
Since C++11, non-const rvalue references can be declared to bind rvalues. A successful binding implies the caller no longer needs the value and it may be stolen. This was mainly to avoid implicit deep copies of temporaries (which are no longer needed after a function call) instead of just using the temporary’s data.
template<typename T>
class Socket
{
public:
...
// copy message into buffer
void copy_message(const T& message);
// move message into buffer
void move_message(T&& message);
};
int main(){
Socket<std::string> s1;
std::string m = getMessage();
...
s1.copy_message(m); // copy m into s1
s1.move_message(getMessage()); // move temporary into s1
s1.move_message(m+m); // move temporary into cell
...
move_message binds the temporaries getMessage() and m+m, so they are never copied from but only the memory used by them is stolen.
Now, we can also do the same thing with the lvalue m as follows.
...
#include <utility>
s1.move_message(std::move(m)); // move m into s1
std::move(x) basically means “I am not going to use x anymore” and the resources of x are free to be moved. It returns an rvalue reference which binds with move_message, also known as,
- xvalues are (mostly) returned rvalue references created by
std::move.
This operation leaves with original lvalue in a valid but unspecified state. It can be reused if you want to, for example, if we’re reading from a file,
// read line-by-line from standard input and store in client socket buffer
Socket<std::string> s2;
std::string line;
while (std::getline(std::cin, line)){ // read next line from stdin
s2.move_message(std::move(line)); // move it to buffer inside socket
}
Finally, we circle back to call by reference and look at the convention enforced by the compiler of functions overloading different value categories.
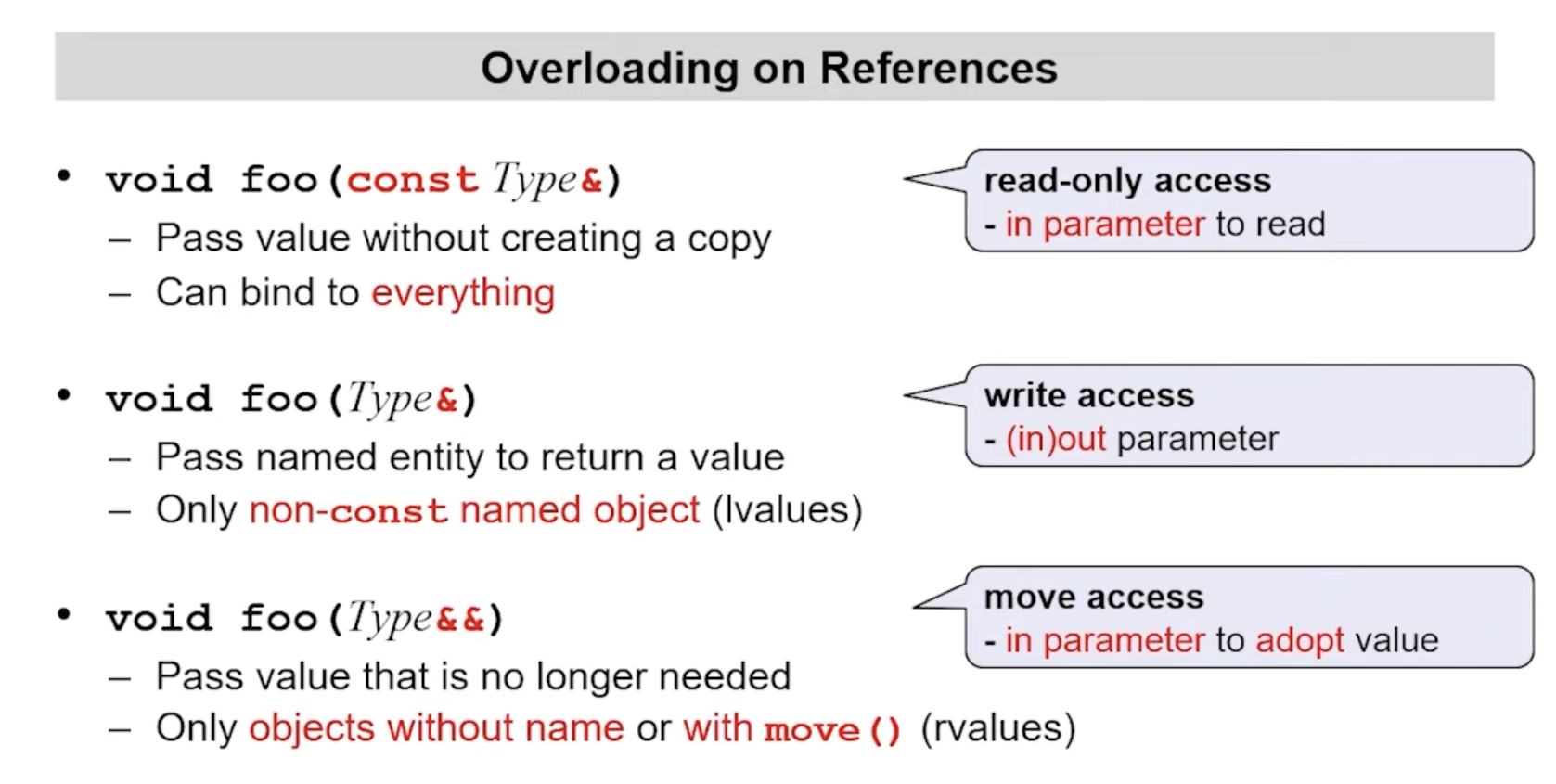
Some interesting observations we can make is that Type& only binds modifiable lvalues and non-modifiable lvalues are only bound to const Type&. Secondly, if rvalues fail to bind with Type&&, then they call fall back to const Type& which implements a copy constructor.
Getting back to our initial questions which led us here, we have answered our first question comprehensively. The second question about assinging an rvalue of type std::unique_ptr to std::shared_ptr is cleared from this simple block of code in cppreference.
template< class Y, class Deleter >
shared_ptr( std::unique_ptr<Y, Deleter>&& r );
This move constructor, which accepts an rvalue reference, creates a std::shared_ptr which manages the object currently managed by r.
Delete(key)
Delete the value for the key. This method returns a new trie.
This isn’t straightforward and requires a bit of thought. Our main beef is with a chain of empty nodes attached to an empty leaf (terminal) node. We need to delete all of these in the new trie. How do we decide the node below which the cut needs to happen? Let’s call this cut_node which must satisfy either of these properties:
cut_nodemust contain a value and can have any number of children, or,cut_nodemust be empty and have more than one child
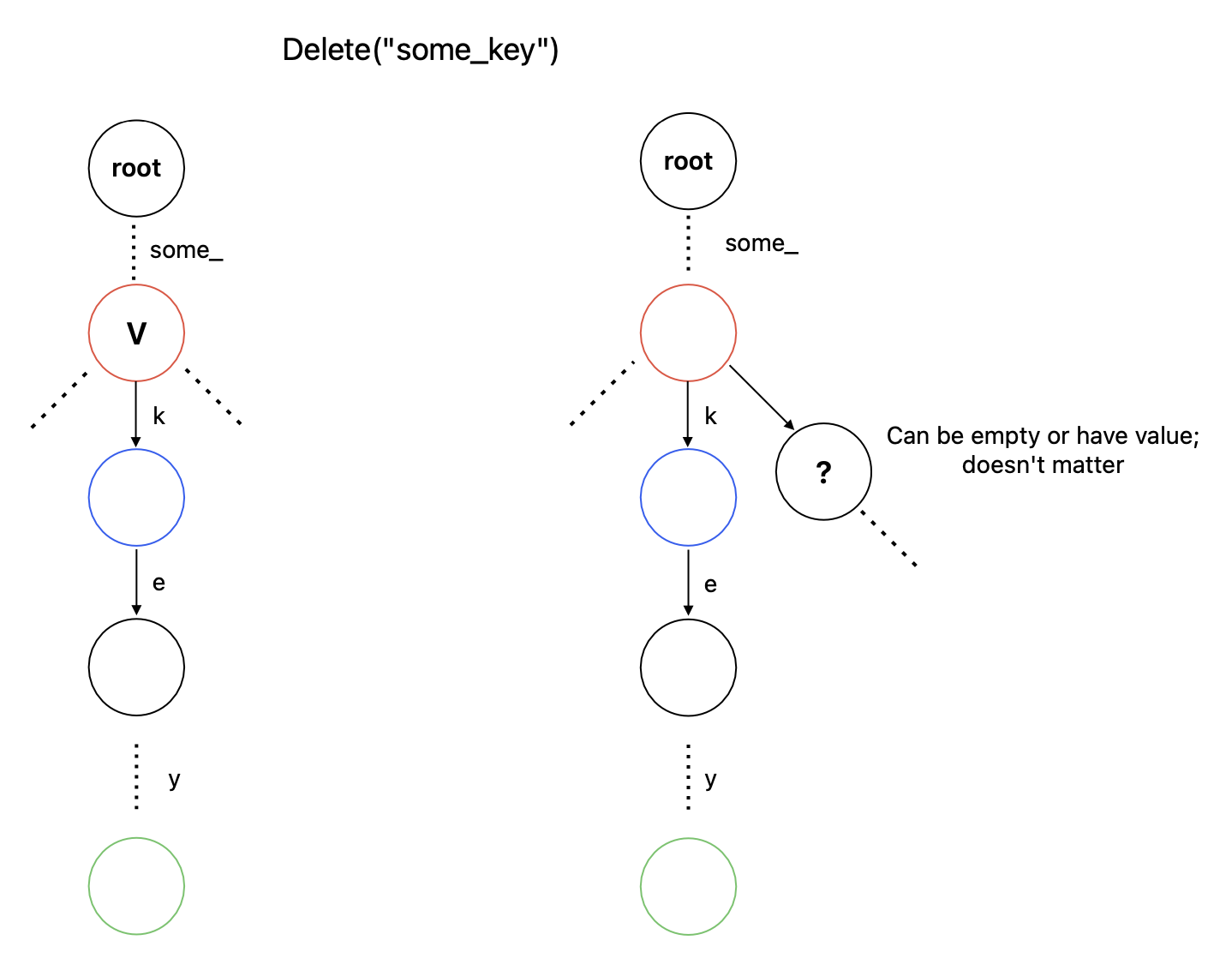
This is not so hard to write down,
// keep track of the cut path which consists of cut_node and cut_child
if (node->has_value || node->children.size() > 1) {
cut_node = node;
cut_child = next_char_in_the_key;
}
and when this path needs to deleted,
if (node->children.empty()) { // reached leaf node
cut_node->children.erase(cut_child); // cut all descendants below cut_node from cut_child to leaf node
}
and we’re done.
Serving concurrent users 🚧🔨
Image credits
- Copy-on-write with data blocks mapped using inodes - John Kubiatowicz, CS162 UCB Spring 2023
- Operations do not directly modify the nodes of the original trie - Andy Pavlo, CMU 15-445
- VTable layout (under the Itanium C++ ABI) - Leonard Chan, Fuschia
- Value categories since C++11 - Nicolai Josuttis, Universal/Forwarding References, Meeting C++ 2022
- Overloading on references - Nicolai Josuttis, Universal/Forwarding References, Meeting C++ 2022